The architecture behind modern AI
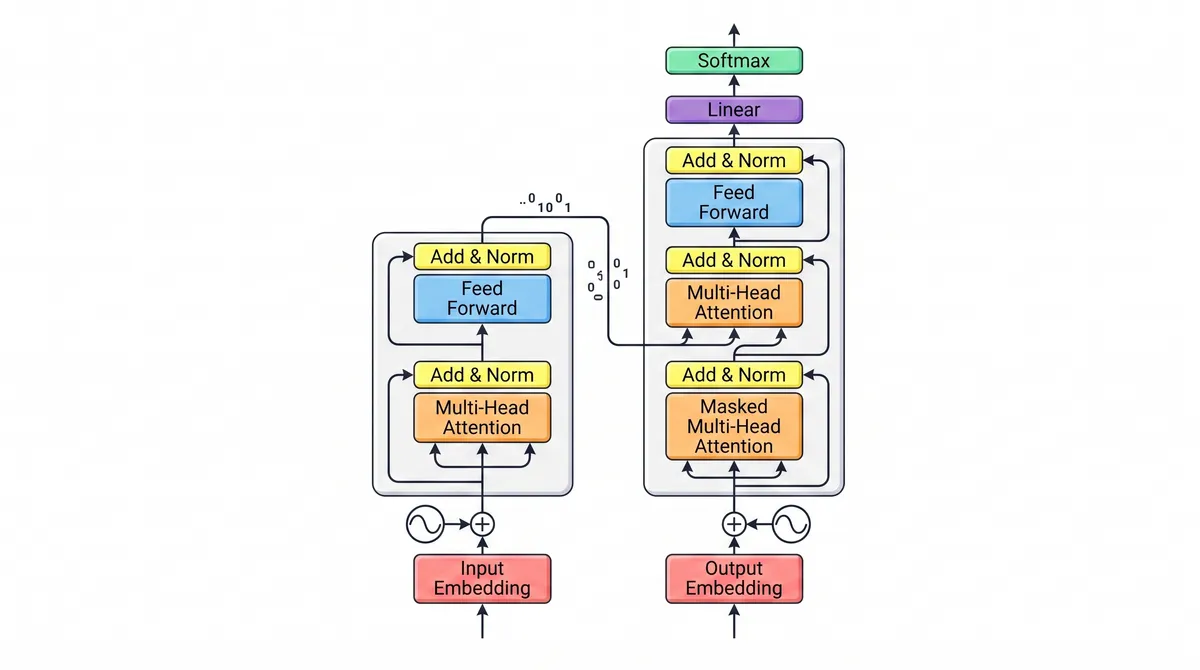
The Transformer is the neural network architecture introduced in the 2017 paper “Attention Is All You Need”, and it is the foundation of nearly every modern LLM. Its key innovation is the attention mechanism, which lets the model weigh how much each word in a sequence should influence every other word.
Before Transformers, models processed text strictly in order, which made long-range relationships hard to capture. Attention removes that bottleneck: every token can look at every other token in parallel, so the model can connect “it” to the noun it refers to even if they are far apart.
Why it changed everything
Two properties made Transformers dominant:
- Parallelism — they process whole sequences at once, which makes them efficient to train on modern hardware.
- Scalability — performance keeps improving as you add more data and parameters.
That scalability is exactly what made today’s LLMs possible, and why embeddings, RAG and agents all ultimately sit on top of this single architecture.