La arquitectura detrás de la IA moderna
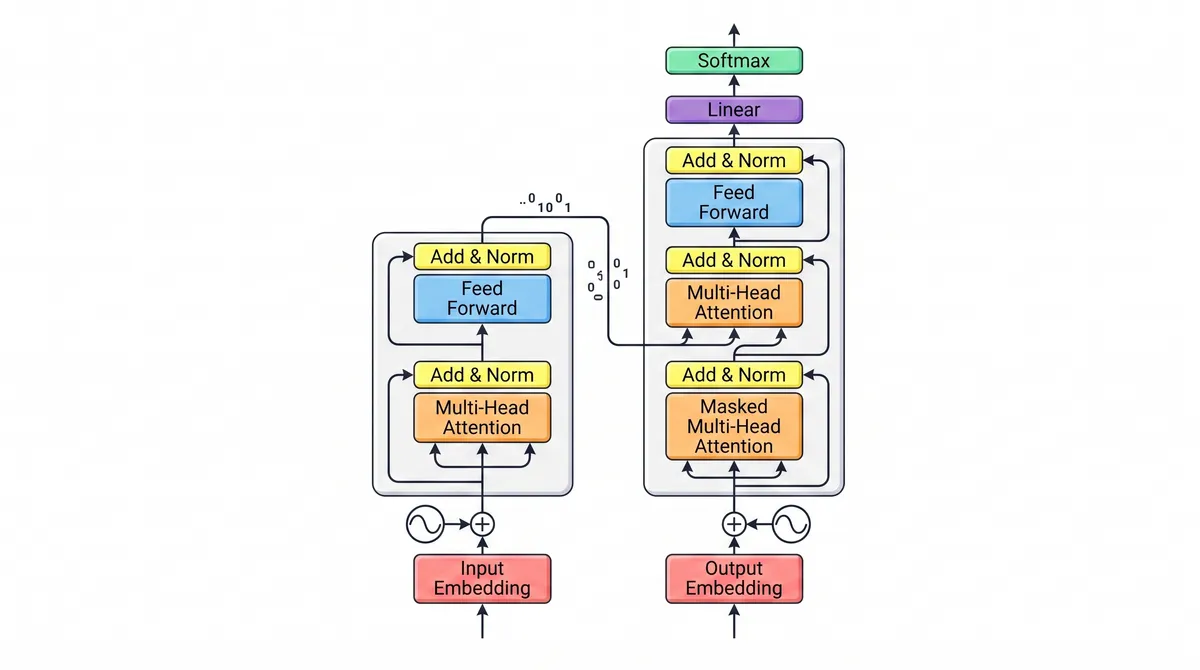
El Transformer es la arquitectura de red neuronal presentada en el paper de 2017 “Attention Is All You Need”, y es la base de casi todos los LLMs modernos. Su innovación clave es el mecanismo de atención, que permite al modelo ponderar cuánto debe influir cada palabra de una secuencia sobre todas las demás.
Antes de los Transformers, los modelos procesaban el texto estrictamente en orden, lo que dificultaba capturar relaciones a larga distancia. La atención elimina ese cuello de botella: cada token puede mirar a todos los demás tokens en paralelo, de modo que el modelo puede conectar “lo” con el sustantivo al que se refiere aunque estén lejos.
Por qué lo cambió todo
Dos propiedades hicieron dominantes a los Transformers:
- Paralelismo — procesan secuencias completas a la vez, lo que los hace eficientes de entrenar en hardware moderno.
- Escalabilidad — el rendimiento sigue mejorando a medida que añades más datos y parámetros.
Esa escalabilidad es justamente lo que hizo posibles los LLMs de hoy, y por la que los embeddings, el RAG y los agentes se apoyan, en última instancia, sobre esta única arquitectura.