Data as direction and distance
In machine learning a vector is simply an ordered list of numbers that locates a piece of data as a point in space. When that vector is an embedding, its position encodes meaning — so similar items end up close together and unrelated ones end up far apart.
This is powerful because it turns fuzzy questions like “which documents are about this topic?” into a precise geometric one: “which points are nearest to this point?”
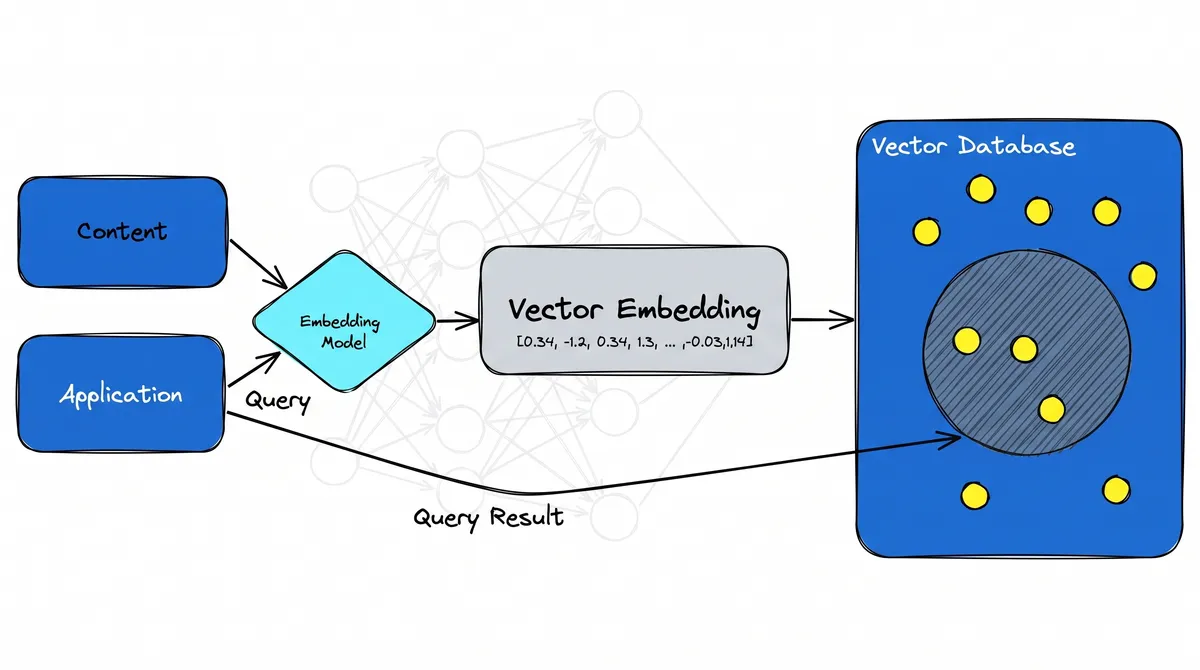
Vector databases
A vector database is a system designed to store millions of these vectors and find the nearest ones to a query almost instantly, using approximate nearest-neighbor (ANN) algorithms. Tools like FAISS, pgvector, Pinecone and Qdrant all solve this problem.
This is the storage layer that makes RAG practical: documents are embedded once and indexed, and at query time the database returns the most relevant chunks in milliseconds — even across huge collections. Vectors, embeddings, and the Transformer models that produce them are the three pieces that fit together to power modern semantic AI.