Los datos como dirección y distancia
En machine learning un vector es simplemente una lista ordenada de números que ubica un dato como un punto en el espacio. Cuando ese vector es un embedding, su posición codifica significado, de modo que los elementos similares quedan cerca y los no relacionados quedan lejos.
Esto es poderoso porque convierte preguntas difusas como “¿qué documentos tratan sobre este tema?” en una pregunta geométrica precisa: “¿qué puntos están más cerca de este punto?”
Bases de datos vectoriales
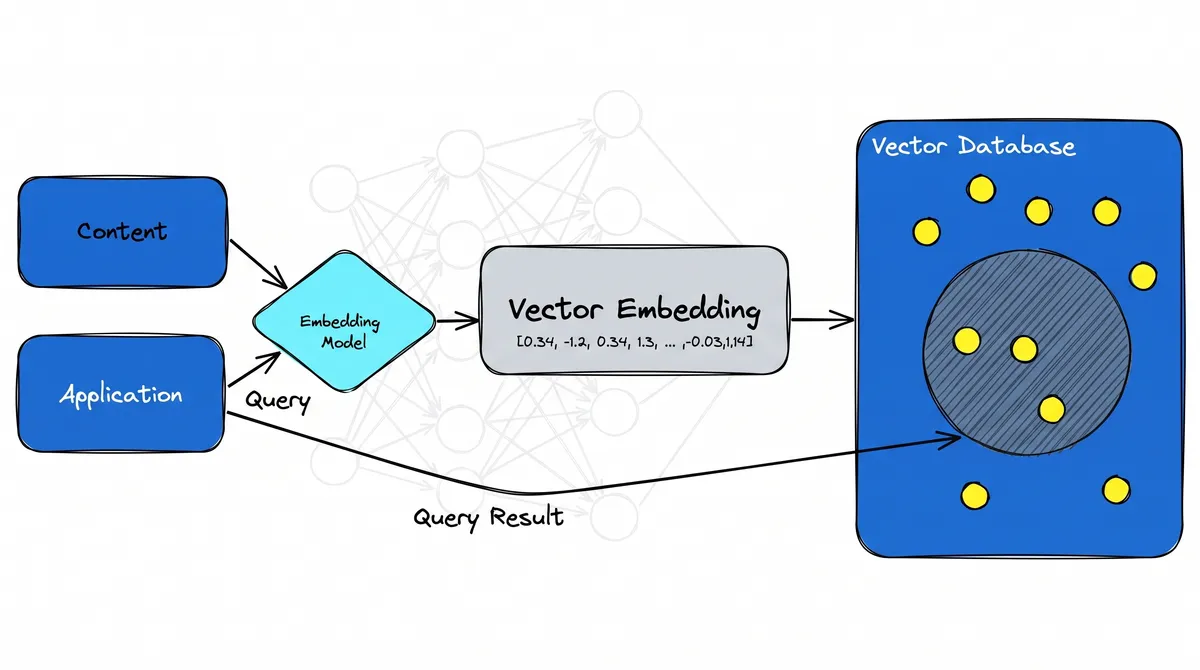
Una base de datos vectorial es un sistema diseñado para almacenar millones de estos vectores y encontrar los más cercanos a una consulta casi al instante, usando algoritmos de vecinos más cercanos aproximados (ANN). Herramientas como FAISS, pgvector, Pinecone y Qdrant resuelven este problema.
Esta es la capa de almacenamiento que hace práctico al RAG: los documentos se convierten en embeddings una vez y se indexan, y al momento de consultar la base devuelve los fragmentos más relevantes en milisegundos, incluso en colecciones enormes. Los vectores, los embeddings y los modelos Transformer que los producen son las tres piezas que encajan para impulsar la IA semántica moderna.